Correlations is a measure of the association between variables. They measure to what extent one variable is affected by a change in another variable. In this article, we will explain the importance of data correlation in machine learning, and introduce four common methods to calculate your data correlation.
Why Data Correlation is Important?
Understanding which variables affect the target we want to predict allows us to choose the right factors to investigate and include in our model, which can significantly improve model performance. We would also like to compare these specific variables to all other variables within the dataset, and even across different machine learning problems for reference. Therefore, it is very useful to have a measurable representation of the association between variables. In this short article, we will discuss four of the most common methods of measuring data correlation.
1. Pearson Correlation
It is a measure of the linear correlation between two sets of numeric data. It can take values between -1 and 1. A value of 1 indicates a perfect positive relationship between the two variables, a value of -1 indicates a perfect negative relationship, and a value of 0 indicates no linear relationship between the two variables.
How to Calculate:
# Import important packages
from scipy.stats import pearsonr
import numpy as np
# Set seed
np.random.seed(10)
# Prepare data
a = np.random.normal(0, 1, 1000)
b = a + np.random.normal(2, 1, 1000)
# Calculate correlations
corr, _ = pearsonr(a, b) # 0.71164274151035742. Spearman Correlation
A measure of the linear correlation between the ranks of two sets of numeric data. It is very similar to the Pearson Correlation, except of directly measuring the correlation, it instead measures the Pearson Correlation of the rankings of the variables.
The ranking of a variable is the assignment of ordering (0, 1, 2, …) to different observations of the variable in question. As an example, the ranking of the data [5, 15, 6, 20] would be [1, 3, 2, 4].
Unlike the Pearson Correlation, the Spearman Correlation can measure non-linear relationships between variables, but still requires the relationship to be monotonic. It can take values between -1 and 1. A value of 1 indicates a perfect positive relationship between the two variables, a value of -1 indicates a perfect negative relationship, and a value of 0 indicates no monotonic relationship between the two variables.
How to Calculate:
# Import important packages
from scipy.stats import spearmanr
import numpy as np
# Set seed
np.random.seed(10)
# Prepare data
a = np.random.normal(0, 1, 1000)
b = a + np.random.normal(2, 1, 1000)
# Calculate correlations
corr, _ = spearmanr(a, b) # 0.69048901848901863. Correlation Ratio
It is a measure of the correlation between a categorical column and a numeric column. It measures the variance of the mean of the numeric column across different categories of the categorical column. Unlike the Pearson and Spearman Correlations, the Correlation Ratio is unable to measure the “direction” of the correlation, and can only measure its magnitude. It can take values between 0 and 1. A value of 1 indicates that the variance in the numeric data is purely due to the difference within the categorical data. A value of 0 indicates that the variance in the numeric data is completely unaffected by any differences within the categorical data.
How to Calculate:
import numpy as np
# Set seed
np.random.seed(10)
# Prepare data
a = np.random.choice([0, 1], 1000)
b = a + np.random.normal(2, 1, 1000)
# Define correlation ratio function
def correlation_ratio(categorical_feature, numeric_feature):
cats, freqs = np.unique(categorical_feature, return_counts=True)
numeric_mean = np.mean(numeric_feature)
sig_y_bar = 0
for i in range(len(cats)):
category_mean = np.mean(numeric_feature[categorical_feature == cats[i]])
sig_y_bar += np.square(category_mean - numeric_mean) * freqs[i]
sig_y = np.sum(np.square(numeric_feature - numeric_mean))
statistic = np.sqrt(sig_y_bar / sig_y)
return statistic
# Calculate correlations
corr = correlation_ratio(a, b) # 0.47243262086211074. Cramer’s V
It is a measure of the correlation between two categorical columns. Based on the chi-squared metric, the Cramer’s V statistic “scales” the chi-squared to be a percentage of its maximum possible variation. It can take values between 0 and 1, with 1 indicating a complete association between the two variables, and a 0 indicating no association.
How to Calculate:
import numpy as np
import pandas as pd
from scipy.stats import chi2_contingency
# Set seed
np.random.seed(10)
# Prepare data
a = np.random.choice([0, 1], 1000)
b = np.random.choice([0, 1], 1000)
# Define Cramer's V function
def cramerv(a, b):
contingency = pd.crosstab(index=[a], columns=[b])
chi2 = chi2_contingency(contingency)[0]
n = np.sum(contingency.values)
r, k = contingency.shape
statistic = np.sqrt((chi2 / n) / min(r - 1, k - 1))
return statistic
# Calculate correlations
corr = cramerv(a, b) # 0.020319325612177513The Cramer’s V is a heavily biased estimator and tends to overestimate the strength of the correlation. Therefore, a biased correction is normally applied to the statistic, shown below
import numpy as np
import pandas as pd
from scipy.stats import chi2_contingency
# Set seed
np.random.seed(10)
# Prepare data
a = np.random.choice([0, 1], 1000)
b = np.random.choice([0, 1], 1000)
# Define Cramer's V function
def cramerv_corrected(a, b):
contingency = pd.crosstab(index=[a], columns=[b])
chi2 = chi2_contingency(contingency)[0]
n = np.sum(contingency.values)
r, k = contingency.shape
phi2 = chi2 / n
phi2_corrected = max(0, phi2 - (k - 1) * (r - 1) / (n - 1))
r_corrected = r - (r - 1) ** 2 / (n - 1)
k_corrected = k - (k - 1) ** 2 / (n - 1)
statistic = np.sqrt(phi2_corrected / min(r_corrected - 1, k_corrected - 1))
return statistic
# Calculate correlations
corr = cramerv_corrected(a, b) # 0.0
Conclusion
As we can see, there are many different ways of calculating the correlation between two variables to gain a better understanding of your data. However, it’s time consuming to manually choose the right approach and calculate the correlation for hundreds of variables.
EvoML automatically calculates these correlation statistics and generates interactive visuals, so you can easily understand the importance of data relationships, while saving time to focus on more important tasks such as selecting the right features for better model performance.
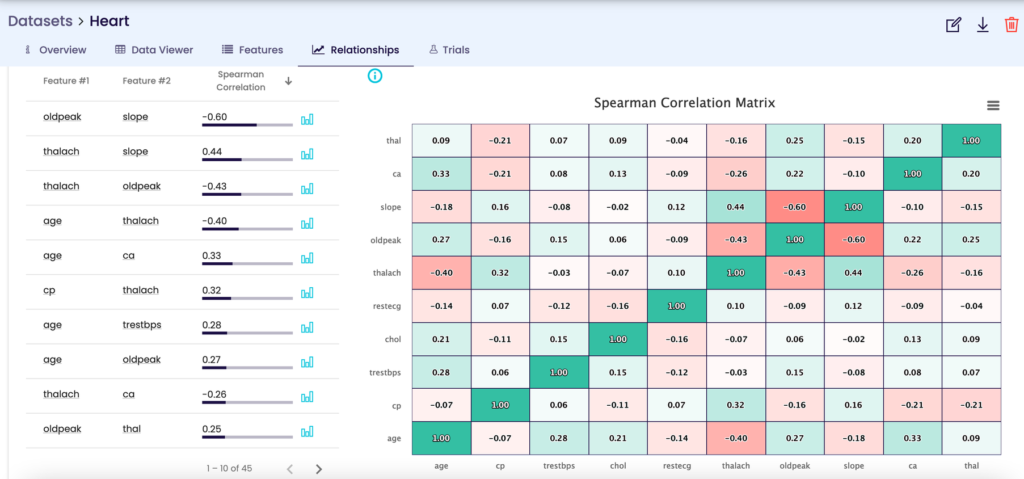
Data Correlation Analysis on EvoML Platform
About the Author
Harvey Eaton Uy | TurinTech Research Team
Data Scientist with a Masters in Financial Economics and a Bachelor’s Degree in Mathematics